「遺伝アルゴリズム」の比較
先ほどのページでは、「遺伝アルゴリズム」には、様々な学習方法があると述べました。
では、いったいどのような学習方法がよいのか。いくつか比較してみました。
検証で使用するもの
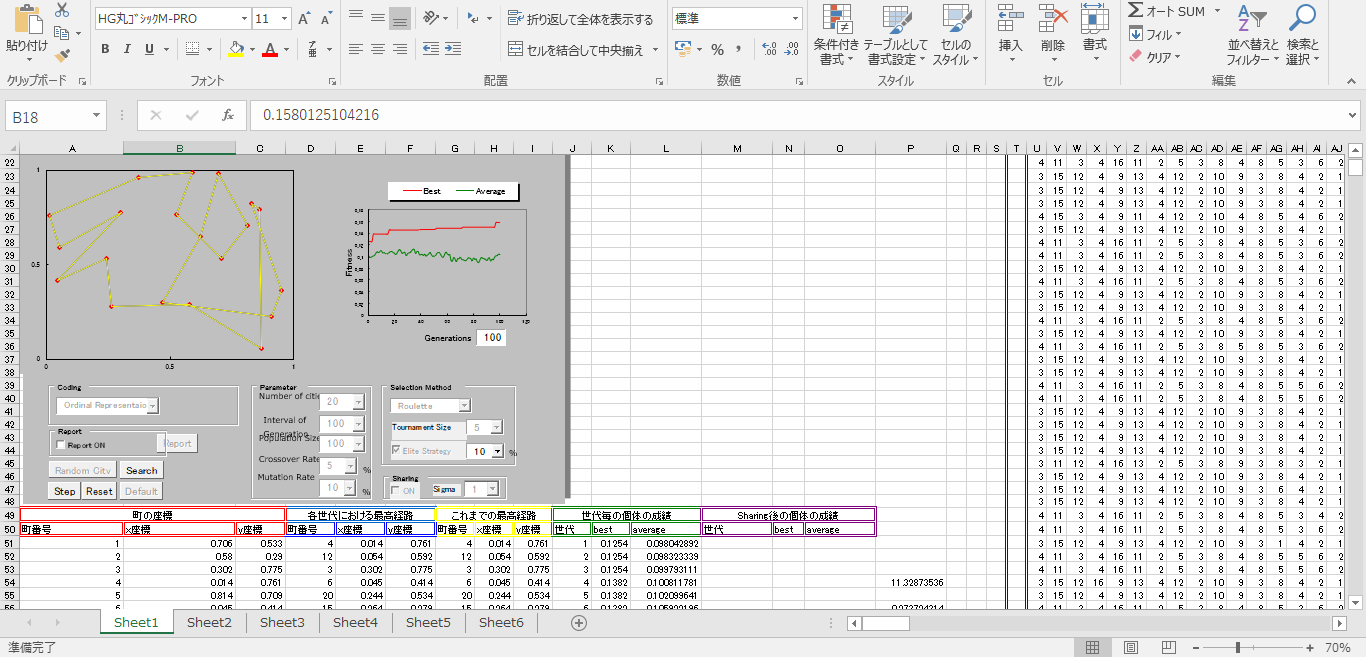
今回検証で使用するものは、東京大学大学院情報理工学系研究科電子情報学の専攻教授である、伊庭 斉志氏より使用と掲載の許可をいただいた、TSPシミュレーションを使用します。
このシミュレーションは、「遺伝アルゴリズム」で巡回セールスマン問題を解決するために、Excelで開発されたもので、突然変異・交叉を行う確率、または、親データの選択方法などを設定できます。
またこのシミュレーションでは適合度は、適合度=1/距離で出力されます。
また今回の検証では、1×1(今回この場ではわかりやすいように500(m)×500(m)で距離を出力)の範囲に、20の訪問地がある設定となっております。
選択方法による違い
検証方法
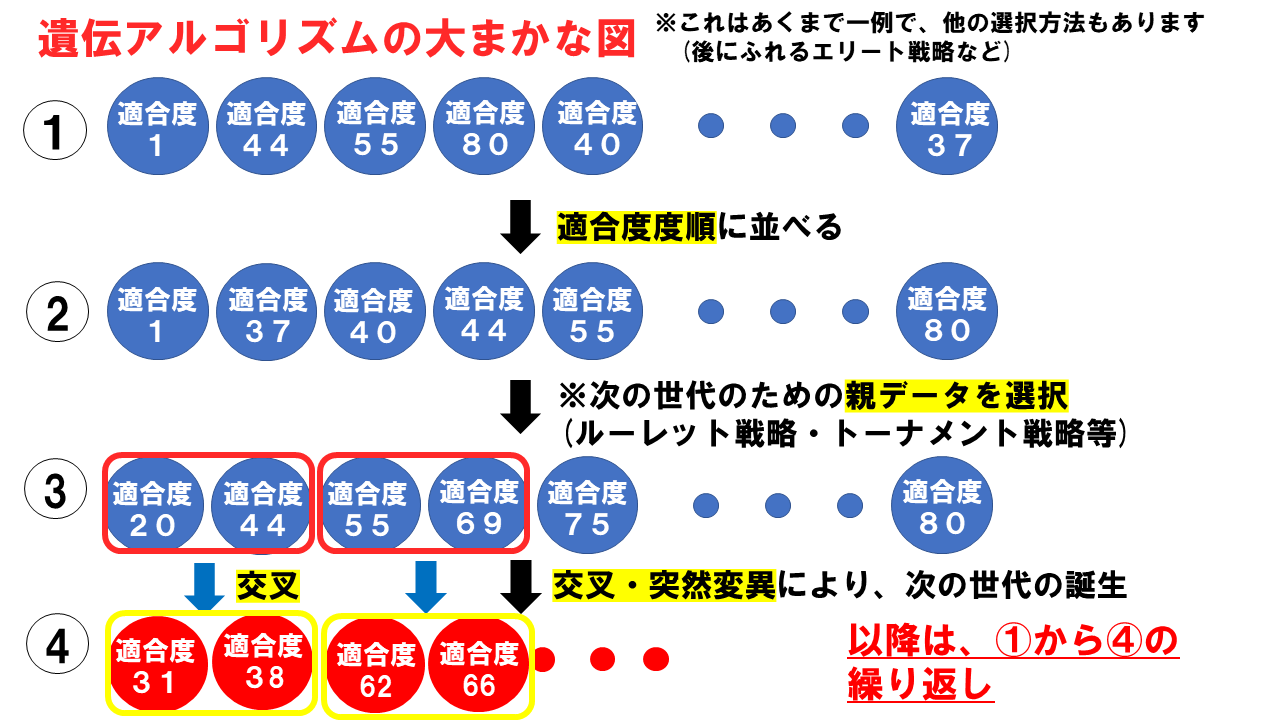
ここでは、上の図の中で、➁と➂の間にあたる親データの選択方法を変えていきたいと思います。
親データの選択方法には、先ほども述べた通り、主に3種類あります。
- ランダム選択
- ルーレット選択
- トーナメント選択
結果

考察
上の表より、トーナメント選択の適合度が最も高かった。
これはおそらく、ルーレット選択とは異なり、任意の数から確実に適合度が高いものを選んでいるから、と推測できる。
交叉率(こうさりつ)の違い
検証方法
ここでは、上の図の中で、➂と➃の間にあたる交叉率を変えていきたいと思います。
またそれと同時に、比較のために選択方法も変えていきます。
交叉率とは読んで字のごとく、
選択されたデータのうち、どのくらいの割合で交叉が発生するかというものです。
結果



考察
上の表より、どの選択方法においても、交叉率が高いほど、おおむね適合度が高かった。
これはおそらく、交叉することによって、次々と新しいデータが生成されていく機会が増えたがゆえに、適合度が高いものを求める確率が上がった、と思える。
突然変異率の違い
検証方法
ここでは、上の図の中で、➂と➃の間にあたる突然変異率を変えていきたいと思います。
またそれと同時に、比較のために選択方法も変えていきます。
突然変異率とは読んで字のごとく、
選択されたデータのうち、どのくらいの割合で突然変異が発生するかというものです。
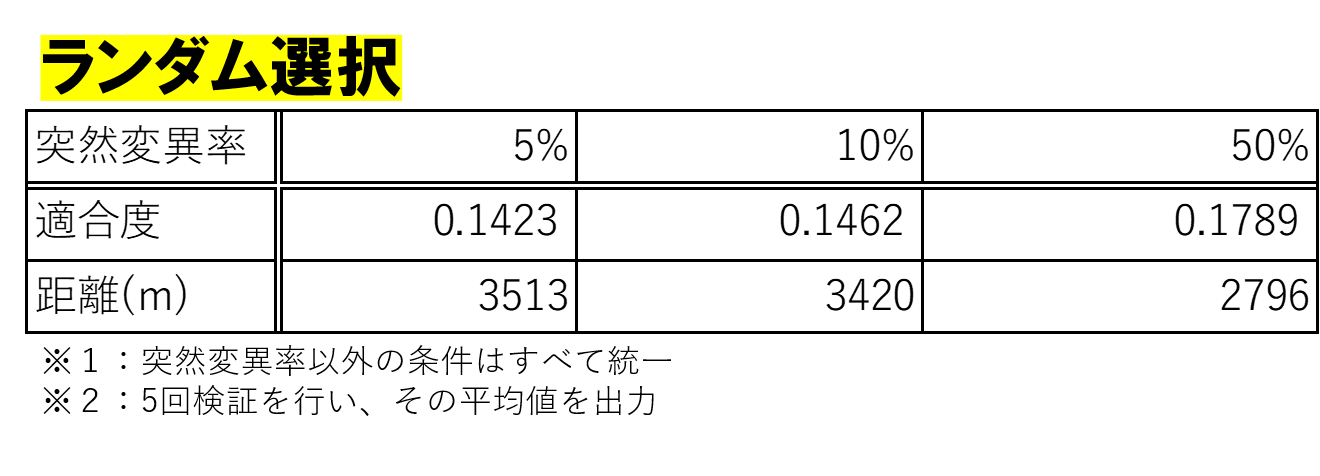
結果


考察
上の表より、どの選択方法においても、突然変異率が高いほど、おおむね適合度が高かった。
これはおそらく、先ほどの交叉率と同様、突然変異することによって、次々と新しいデータが生成されていく機会が増えたがゆえに、適合度が高いものを求める確率が上がった、と思える。
検証を終えて
「遺伝アルゴリズム」の学習方法によって、最大でおおよそ400mほどの差が出ていることが、この検証よりわかりました。
「なんだこれしか差がないのか」と思っている人もいるでしょう。
しかし、これが毎日続くと、とても大きな距離の差となってしまいます。
よって、どの学習方法するか考慮することを怠れば、年間でかなりの時間や燃料をムダにすることになるのです。
今回はそれぞれ5回ずつ出力した結果ですのでかなり有効なデータだと思いますが、
「遺伝アルゴリズム」は確率的な部分もあり、今回の検証結果のようにはいかないこともあり得ます。
また2017年に入り、ヤマトなどが配送計画システムにAIを試験的に導入しました。しかしそれは今回のように単純に距離だけを考慮しているわけでなく、配達場所や指定時間などの条件込みで、最適ルートを出力してくれるみたいです。
しかし、現場の声からは、「機械的に回ればいいってもんじゃない」「半年も経験を積んだドライバーには、無用の長物になりそうだ」と言ったものもあり、「遺伝アルゴリズム」のようなAI導入にはまだまだ課題はたくさんあります
将来的にはドローンで宅配する機会やドライバーの労働負担が増えるとされています。ドローンに関しては道路に関係なく、ほぼ自由に飛行できるので、一層適切なルートを考える必要性が出てきます。また今後、通販などの普及により、今後より一層労働負担が増えることについても、「遺伝アルゴリズム」を使えば、配達ルートをある程度短縮でき、ドライバーの負担も減るので、前述した課題を考慮しながらも物流業界で今後一層「遺伝アルゴリズム」などのAIの導入もしくは改良が進めばよいと思います。
- 「遺伝アルゴリズム」の学習方法によっては、トータルで(年間単位)見ると結果(距離)がかなり異なる。
- 「遺伝アルゴリズム」の学習方法を最適化することで、様々なメリットが得られる
戻る検証次へ