文字コード
コンテンツのデジタル化も終盤だね。最後にやるのは文字コードだよ。


文字コードって、あのUTF-8とかの話ですか?
よく知っているね。その通りだ。文字コードではどうやってコンピュータが文字を表現するのかを学ぶぞ。

なんか、これもこれで難しそう…
コンピュータの文字コード
コンピュータの世界には0、1の電気信号がついているか、ついていないかの二つしかないため、人間の文字を表現することができない。そのため、コンピュータ上で人間の言語を表現するためにはコンピュータの使う0と1の電気信号によって扱えるように記号として人間の文字を表現させる必要がある。そこで使われるのが、二進数で文字を指定する文字コードである。 文字コードを用いる事によって文字という記号をデータとしてコンピュータで扱うことが出来るようになり、文字の「デジタル化」が行える。文字コードそのものはコンピュータが人間の言葉を表現するための英和辞典のようなものだと思えば分かりやすいかも知れない。文字コードの例には以下のようなものがある。
①ASCII(American Standard Code for Information Interchange)
ASCIIは、アルファベット、数字、句読点などの基本的な文字を表現するために1963年に開発された世界初の文字コード。各文字には7ビットの数値が割り当てられていて、今でもそのシンプルさ故にプログラミングの際の変数名やコメントアウトに使われている。
②Unicode
Unicodeは、世界中のさまざまな言語や記号を扱える文字コード。Unicodeでは、各文字に16進数の符号点というプログラミングで言う変数のようなものが与えられる。Unicodeはあくまで、符号点を集めた表のようなものであるため、コンピュータはUnicode単体では使えず、符号化を行って二進数に直す必要がある。
③UTF-8 (Unicode Transformation Format - 8-bit)
UTF-8はUnicodeの符号点の符号化を行う方式の一つで、可変長の二進数に直すのが特徴である。ASCIIと互換性があるため、手順を踏まずにASCIIに変換することができる。
④ISO-8859 シリーズ
ASCIIをベースにして各国の言語に対応できるように拡張された文字コードのシリーズ。様々な文字、言語に対応した文字コードが存在している。
文字が多くなってしまったけど、ついてこれたかな?
探Q
文字コードを極めろ!
私はこのページを書くためにUTF-8について調べていたとき、UTF-8が厳密には文字符号化方式というものであることを知った。このページを読んだ皆様は「え?文字コードちゃうん?」と思ったかもしれない。今回は文字コードについてさらにさらに細かく見ていこう。
まずはそのためにも文字コード自体についての用語をきちんと理解しよう。
文字コード:人間の文字をコンピュータが理解できるように文字ごとに識別番号を与えて区別できるようにしたときの文字と識別番号、または識別番号とデータの対応関係の規則のこと。
符号化点:個々に識別した文字に割り当てられる識別コードのようなもの。この段階ではまだコンピュータは理解できないため、後述のバイナリデータに変換する必要がある。バイナリデータ:1と0の状態になったデータのこと、文字はバイナリデータになってはじめてコンピュータが理解できるようになる。
文字符号化集合:文字と符号化点の対応表のようなもの。文字にはA、B、あ、いのような図形文字と改行やスペースといったような制御文字があり、全てに符号化点が振られている。Unicodeは文字符号化集合に含まれる。
文字符号化方式: 符号化点とバイナリデータの対応表。符号化点をコンピュータの理解できる状態に翻訳する。UTF-8は文字符号化方式に含まれる。
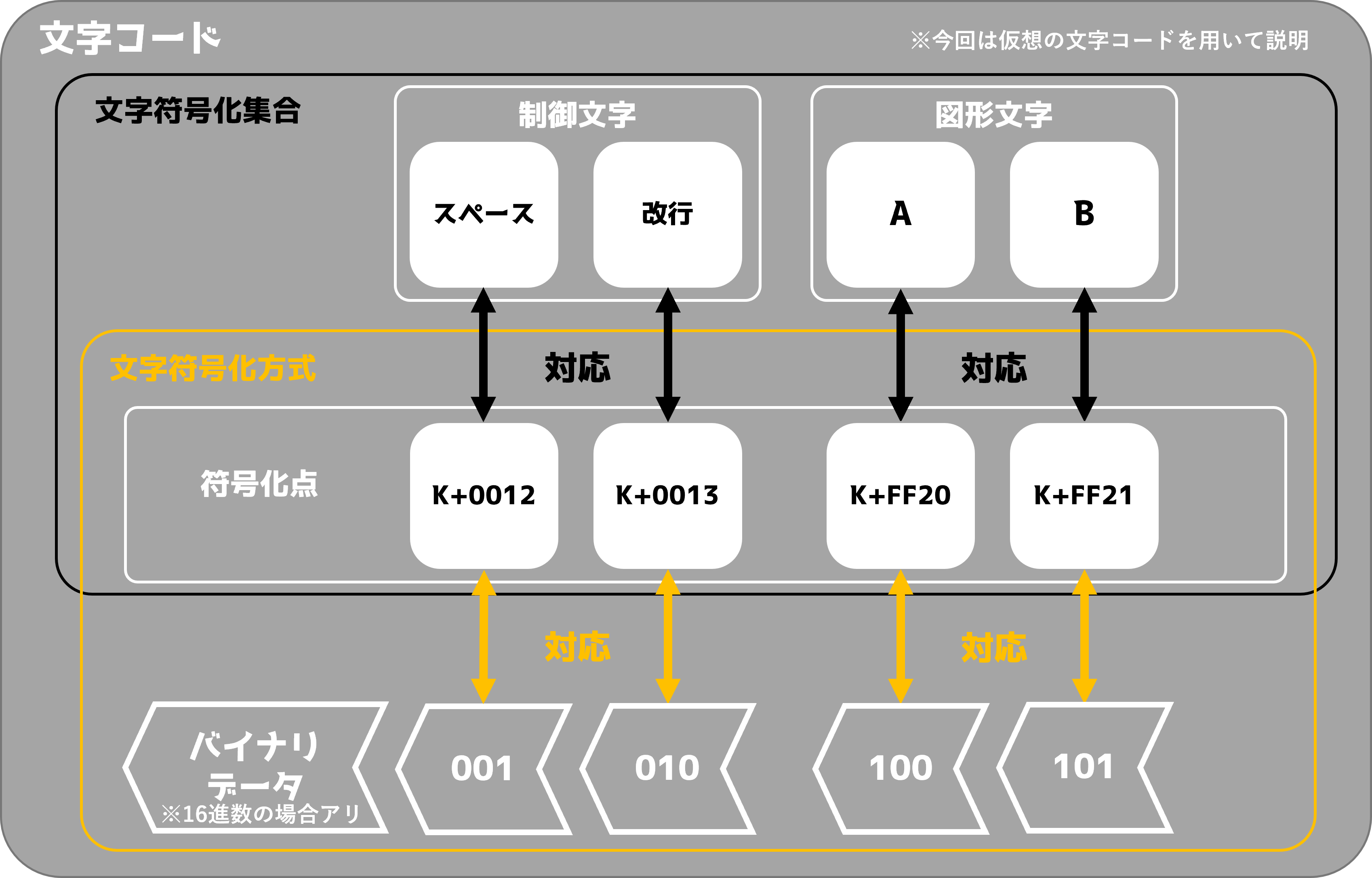
これを踏まえて文字コードの例をもう一度見ていこう
①ASCII(American Standard Code for Information Interchange)
世界初の文字コード。符号化点を使わず、直接バイナリデータと文字を対応させている。まだコンピュータが大学が総力を上げて研究するものだった時代はコンピュータごとに独自の文字コードを使っており、それらを統合する目的で作成された。1文字を7ビットで表現し、英語26文字、英数字、制御文字を含めた127個の文字を対応させている。
②Unicode
世界中の文字に符号化点を対応させている文字符号化集合。Microsoft、Apple、IBMなどの大企業が文字符号化集合を統一する目的で作成した。現在は図形文字だけで約14万個の文字が登録されていて、14万個の中には現代では使われないような古代文字なども登録されている。文字符号化集合はそのほとんどがUnicodeに統合されている。
③UTF~シリーズ(UTF-8を除く)
UTF-16、UTF-32 などが有名な文字符号化方式。UTF-16、UTF-32は符号点をそれぞれ16ビット、3ビットの固定長で表すため、文字数が少ない言語だと最初の10数ビットを無駄にしてしまい、データの効率があまり良くなかった。しかし、固定長であるという特徴が必要な時もあるため、まだ使われている。
④UTF-8
UTF-16、UTF-32の欠点を克服した文字符号化方式。1〜4バイトの可変長で符号化点を表すため、英語のような字数の少ない言語は1バイト、日本語や中国語のように字数の多い言語は4バイトのような使い分けができるようになっている。また、ASCIIと互換性を持たせるため、ASCIIの対応している部分は全く同じに表現するように出来ている。Unicodeの文字符号化方式であるため、現在最も使われているエンコード方式とされている
文字化けとは?
ではまず、文字化けとはなんなのだろうか?文字化けとは読んで字の如く文字が化けるということだ。基本的に文字化けはバイナリデータを元の文字の状態に戻す時に発生し、二つある原因はいずれも文字コードが関係している。
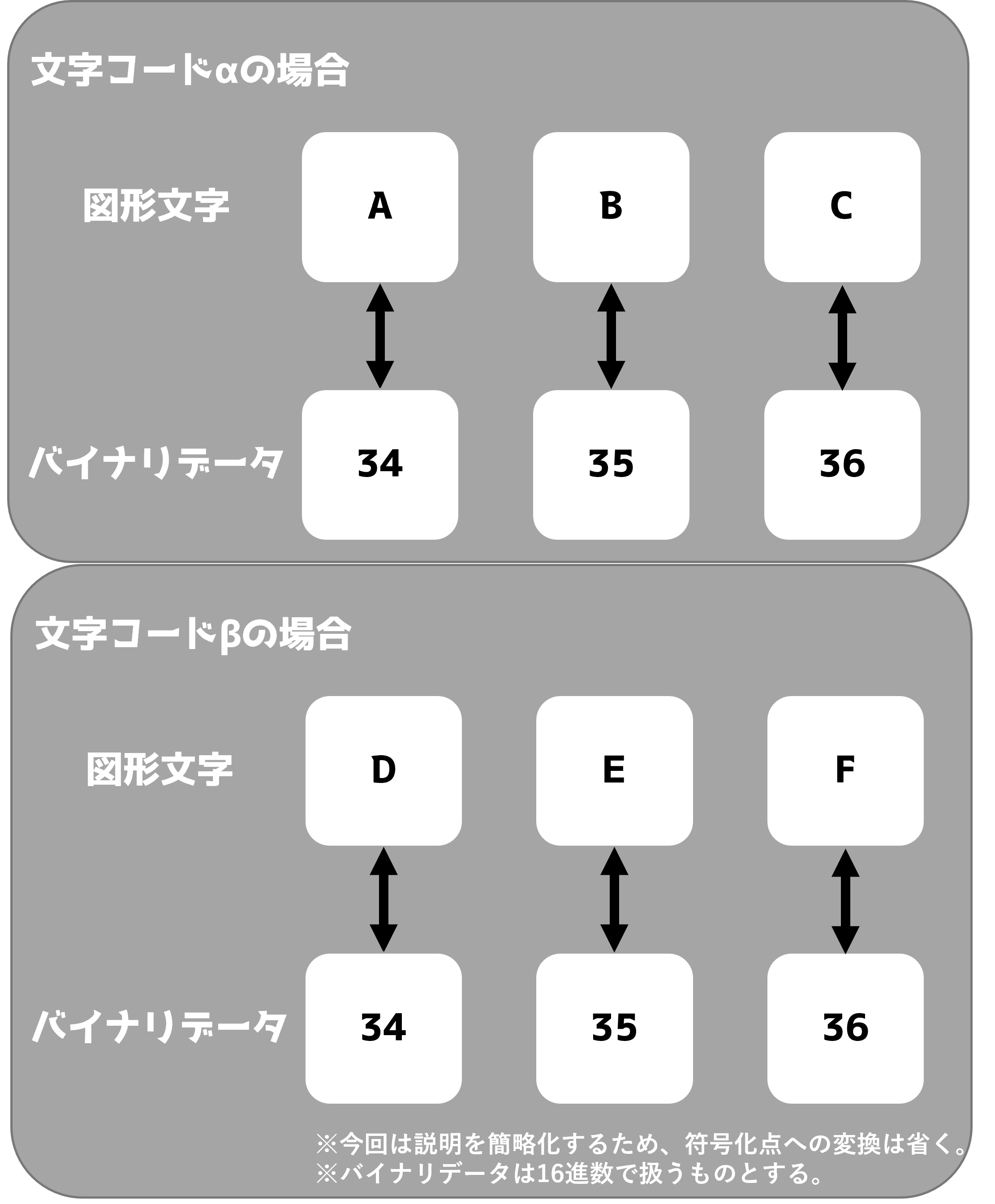
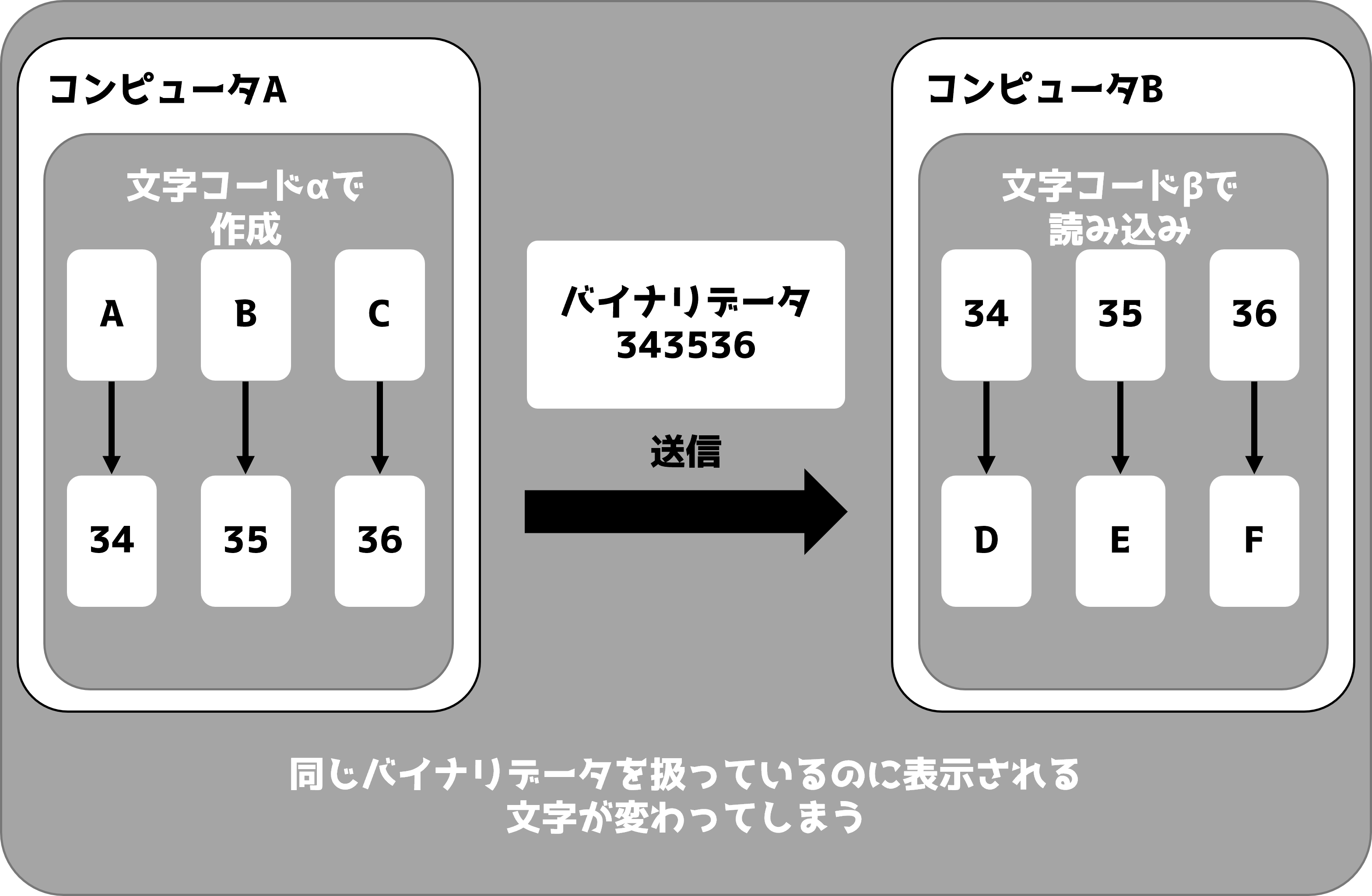
文字化けのイメージは「他のPCに送るためにバイナリデータにしたらそのPCが間違って翻訳しちゃったよ〜; ;」ぐらいに思えば分かりやすいかもしれない。ここでは仮想の文字コードαとβを使ってなぜ文字化けが起こるのかを説明しよう。
まずここに34、35、36というバイナリデータがある。これを文字コードαを用いて対応する文字を出力した場合、A、B、Cという文字列になる。
この場合、文字コードαを使う限り、バイナリデータ34、35、36は必ずA、B、Cとなる。しかし、文字コードβを用いて対応する文字を出力した場合、図のようにD、E、Fとなってしまう。
つまりこういったことが起きる。これこそが文字化けである。
- ①文字コードを用いることでコンピュータでの人間の文字の出力が行える。
- ②世界初の文字コードとしてASCIIは1963年に作られた。

