ディープラーニング 実践(上級者)
上級者向けの概要
上級者向けでは、実際のディープラーニングを活用したシステムなどに近づけるため、Pythonを使用しWindows上でStableDiffusionを実行します。なので、スペックの高いPCとGPUが必要となります。
わざわざ違うものを扱うワケ
端的に言えば、「Google Colab上で行うには限界がある」という点である。
Google Colabで利用できるGPUはVRAMに上限があるため、任意のグラフィックボードで動作することが可能となるWindows上での動作を本ページでは解説します。
要求されるPCスペック
前述の通りかなりの高スペックを要求します。私たちの環境を以下に載せておきます。
CPU:Ryzen 7 3700X
GPU:RTX2060 Super
RAM:32GB
OS:Windows 10
これでも正直足りないくらいなので、このくらいのスペックが最低限だと考えてください。
必要環境
PCスペックは前述の通りですが、その他の要件を以下に載せます。
・Python3(できればPython3.10)をインストール済みであること
・Gitをインストール済みであること
・高速なネット回線があること(光回線推奨)
・HDD/SSDが10GB以上空きがあること
・プロキシのあるネットワークじゃないこと
以上が条件になります。
初心者向けとそこまで大差ないですが、PythonとGitのインストールをしなければなりません。
まだインストールされてない方はこちらの記事とご覧ください。
Pythonのインストール方法 Gitのインストール方法
Stable Diffusion用のフォルダ作成
Gitでソースコードをインストールするのですが、そのための専用のフォルダを用意しましょう。
好きなところにフォルダを作ったら名前をわかりやすい名前にしておきましょう。
フォルダでgitを開く
専用のフォルダを作成し,エクスプローラーでそこに入りましょう。そこで右クリックをし「git bash here」をクリックしましょう。

そこで以下のようにコマンドを打ちます。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
もしここで成功しなかった場合はネットワークの問題が考えられます。プロキシなどを使用している場合はオフにしましょう。
初回起動のセットアップ
実行に少々時間がかかることがありますが、普通の動作なので安心してください。
インストールが完了すると、標準ブラウザでStableDiffusion webUIが起動すると思います。これでインストールは終了です。
モデルのインストール
モデルにはたくさんの種類があり、アニメ調や現実調などたくさんあります。
また、最新のモデルでは「SDXL」というものがあり、高画質かつ幅広いスタイルの画像を出力することができます。
モデルは自分で好きなように作ることもできるのですが、高度な知識が必要になるのでダウンロードしちゃいましょう!
また、今回の上級者向けのStable Diffusionでは、ckptファイルではなくSafetensorsファイルを使います。Safetensorsファイルのほうがより早い読み込みを実現し、安全性が向上しています。
今回は、さきほど紹介したSDXLを使用していきたいと思います。
今回はCivitaiというモデルデータを扱うサイトからダウンロードしたいと思います。
初心者向けで紹介したサイトとは違いますが、こちらは直感的にダウンロードできるサイトになっています。
サイトにアクセスし、検索ボックスにワードを入力し好みのモデルを出力します。
今回私たちが利用したのはCounterfeitXLです。
好みのモデルを見つけれたら、Downloadボタンがあるので押しましょう。そうしたらダウンロードが開始します。
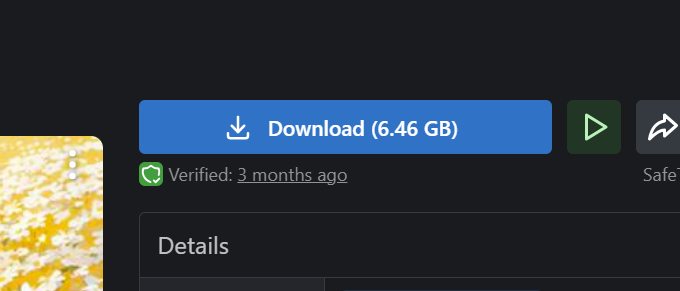 かなり容量が大きいので、高速な回線を用意することを推奨します。
かなり容量が大きいので、高速な回線を用意することを推奨します。
インストールが終了しましたら、所定のフォルダにモデルを移動させます。
Gitを使ってインストールしたファイルの中の「webui」-「models」-「Stable-Diffusion」の中に入れましょう。
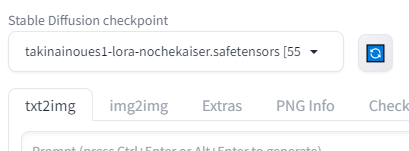
そして最初の起動と同じようにwebui-user.batを実行し、左上のモデルを選ぶリストからダウンロードしたモデルを選択しましょう。
たくさんのモデルを置きたい場合は、その分容量をたくさん使いますので増設しておくことをお勧めします。
実際に出力してみる
実際に出力してみましょう。
今回私たちはSDXLモデルを使用しています。SDXLモデルは従来のモデルとは違い、長いプロンプト(≒たくさんの単語・修飾語)である必要はないので、例えば
「Cute School Students」などと出力するとそれっぽいのがふつうにでてきます。
ですが、GPUのメモリ(VRAM)をたくさん使用するので、すべてSDXLである必要はないんです。
先ほどの工程でインストールしたモデルをリストから選択しました。それを確認しましょう。
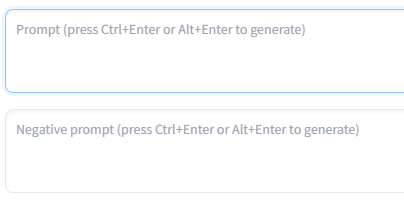
そのすぐ下の欄に「Prompt...」とまたその下に「negative prompt...」とあると思います。この二つのうち、上の方はプロンプトといい、出力したい画像のテキストを入力する場所になります。
その下はプロンプトとは真逆のネガティブ・プロンプトといいます。出力したくない画像のテキストを入力する場所になります。
プロンプトを入力したら、オレンジ色の「Generate」ボタンを押し、出力させましょう。
生成が終了したらフォルダボタンを押し、画像を確認してみましょう。

実はこのままのデフォルトのままだとあんまり真価を発揮しません。StableDiffusionの本気はここからです。
いろいろ変えてみよう
StableDiffusionの細かさをここで教えていきます。
ここですべて紹介しきるのはほぼ不可能なので、一部抜粋して紹介していきます。
Restore Face
これは生成される顔部分に補正処理を行うオプションです。基本的に実写を対象としている機能なので、アニメ調のイラストを生成するときにはOFFにし、実写の画像を生成する際にはONにすることを推奨しています。
Tiling
上下左右につなぎ目を作らず、きれいにつなげられる画像を出力するためのオプションです。今回の用途ではあまり使わないかもしれませんが、模様などを生成していく時には重宝する機能です。人やイラストなどの場合はOFFにするのが望ましいでしょう。
Hires.fix
大きな画像を出力する際に、工程を二段階に分割するためのオプションです。これにより、構造の破綻を抑制し、プロンプトのとおりに画像が生成されやすくなります。基本的に、どんな画像でもONにすることを推奨します。
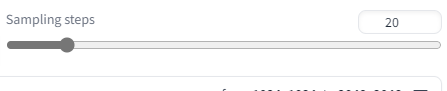
Sampling steps
このパラメーターは画像のノイズを除去する回数をさしています。標準では20回ですね。このパラーメータの値が高ければ高いほどいい画像が生成されますが、逆に時間がかかりますので、ここはまちまちというところだと思います。
Batch count,Batch size
Batch countは一枚の画像を何回生成するか、Batch sizeは一回で何枚生成するかです。VRAMの量などにもよりますが、個人的にはBatch sizeを1に固定し、Batch countを増やすことによってVRAMの使用量を抑制できるので、おすすめしています。
これ以外にもたくさんのパラメーターがあるので、たくさん変えて自分好みの画像を出力してください!